Portfolio item number 1
Short description of portfolio item number 1

Short description of portfolio item number 1
Short description of portfolio item number 2
Published in 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL 2024)
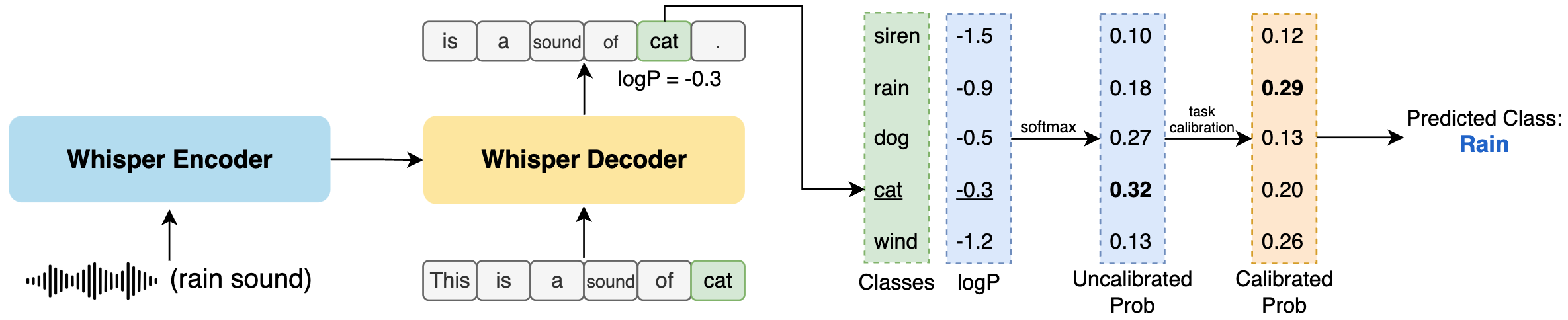
In this work we investigate the ability of Whisper and MMS, ASR foundation models trained primarily for speech recognition, to perform zero-shot audio classification. With simple template-based text prompts, we demonstrate that Whisper shows promising zero-shot classification performance on 8 audio-classification datasets, outperforming existing state-of-the-art zero-shot baseline accuracy by an average of 9%. To unlock the emergent ability, we introduce debiasing approaches. A simple unsupervised reweighting method of the class probabilities yields consistent significant performance gains. We also show that performance increases with model size, implying that as ASR foundation models scale up, they may exhibit improved zero-shot performance.
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.